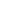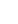发布时间:2019-11-22 14:02:07
发布时间:2019-11-22 14:02:07
基于Chrome扩展的爬虫系统设计与实现
魏少鹏,夏小玲
(东华大学计算机科学与技术学院,上海201620)
摘要:为了提高网页数据抓取效率,降低爬虫对系统资源的消耗,提出了一种基于Chrome扩展的爬虫系统。利用 Chrome浏览器对网页进行解析,防止被爬取对象屏蔽和网页异步加载问题,并且实现数据结构化;通过选择普通用户版扩展和服务器版扩展,既可以实现无人值守主动抓取,也可以在用户浏览网页的同时抓取信息。整个系统前后端分离,并且采用面向接口编程,具有良好的扩展性。通过从搜达足球网站抓取英超赛程,验证了程序的高效可行性。怎么改ip地址
o引言
在大数据时代,信息呈“爆炸”式增长,为企业和个人提供了丰富的信息来源。以新浪微博为例,截至2015年 8月,有注册用户6亿,日均活跃用户6 600万,日均发微博1 . 2亿条I六只通过搜索引擎搜集、获取整合数据非常困难。在大数据时代信息空前丰富的背景下,数据获取,即如何有效整合散落在互联网各个角落的数据,从而为用户提供更为精淮的信息至关重要,解决该问题归根结底涉及到网络爬虫技术[们
网页爬虫几乎与网页技术一同出现,刚开始的爬虫技术主要是利用图论知识,将整个互联网看作一个连通图,采用深度优先或广度优先算法来抓取数据。随着互联网规模的扩大,对采集速度和数据质量要求不断提高,由此出现了主题爬虫,即根据给定的主题,抓取与主题相关的网页。当互联网规模和技术进“一步发展,出现了基于分布式的爬虫,例如Google Crawler、Internet Archive Crawler 文章编号:1672一7800(2016)003一0076一05
等,并且还出现了针对Ajax网站的爬虫,例如Google Groups、Google Suggest等。无论是传统爬虫还是主题爬虫,抑或是分布式爬虫和针对Ajax的爬虫7 ],其核心技术都是使用程序模拟IE浏览器的功能,将URL作为 HTTP请求的内容发送到对方服务器端,然后读取对方服务器端的响应资源图。
但在实际使用中,传统爬虫技术存在很大的局限性:.实现IE客户端模拟难度大,由于网络环境复杂,不仅实现模拟IE客户端的工作很困一,,一。即使调用开源的 API,也是非常繁琐的,而且网页的解析工作也异常困难复杂;O使用场景存在很大局限性湖,比如不能处理包含异步请求的网页、抓取的数据中含有很多脏数据(如通过网页中的URL抓到广告等)、对服务器配置要求高(所有操作都在中央服务器)、容易被抓取对象屏蔽(客户端浏览器模拟不完善)和无法获得网页详情(网页的URL通过 JavaScript动态生成加密信息)等一系列问题;.使用不友好,主要表现是部署难度大,只适合专业用户,不支持用户在浏览网页的同时爬取数据。
员使用,可应用于智慧城市、智慧交通前期阶段的交通基础数据处理。
参考文献:
卫舯,邵春福·考虑交通量随机波动的随机用户均衡配流模型「了.吉林大学学报:工学版,20巧,45(5):] 408 14 ] 3 ·
林宇洪,沈嵘枫,邱荣祖,等·南方林区林产品运输监管系统的研发 CJ ].北京林业大学学报,20,3 3(5):1 30刁3 5.
[ 3」 蓝跹,伍炜·基于交通量特性分析的山地城市交通发展策略0就重庆交通大学学报:社会科学版,20巧(l ):24一26.
林宇洪,林森,景锐,等.木材运输℃卡读写器的开发《.0.福建农林大学学报:自然科学版,2010,3 9(4):,13 5一们&
肖颖,刘晓建.轨道交通客流一预测的扩展反馈四阶役法研究[了].都市快轨交通,20 ]私2 7(5):4 8 51.怎么改ip地址
曹志成.交通量预测中分布交通量预测的儿种计并方法解析冂l .
建筑工程技术与设计,20巧(1 1):1 9 1 2 1 9 ].7 ·
林宇洪,胡连珍,蒋新华,等.基于二维码的农超对接供应链追溯系统的设计的I.黑龙江八一农垦大学学报,20 ] 5.27(6):83 87.孟博翔·基于四阶段法的兰州市雁滩商业圈交通需求预测0 ].交通科技与经济.20 [ 4刁6(2〕:2 7 3 0 · (责任编辑:孙
作者简介:魏少鹏(] 990 “一),男,甘肃天水人,东华大学计算机科学与技术学院石页士研究生,研究方向为计算机软件与数据可视化;夏小玲(1966一),女,上海人,博士,东华大学计算机科学与技术学院教授,研究方向为计算机软件与数据可视化。
第3期 魏少鹏,夏小玲:基于Chrome扩展的爬虫系统设计与实现
针对传统爬虫的以上缺点,设计了基于Chrome扩展的爬虫系统,其优势如下:.实现难度小。因为本身就是基于Chrome浏览器,所以不需要模拟浏览器、解析网页等;O使用局限性小。基于Chrome扩展的爬虫系统本身就是浏览器访问,不仅可以解决对方服务器端对user-agent验证的屏蔽问题,而且可以解决URL带有动态加密信息造成的问题。Chrome扩展的爬虫系统是对解析好的网页信息进行提取,因而只会提取所需要的结构化信息,降低脏数据,提高数据质量。通过控制Chrome扩展中 JavaScript脚本的执行时间,可以解决网页的异步加载问题;.使用友好。因为是基于Chrome的扩展,所以安装非常方便;信息抓取模块不仅有可以自动抓取的服务器版还有普通用户版,普通用户版可以在用户浏览网页时实现信息抓取,降低了对双方服务器的负载。
1系统结构
通过对传统爬虫系统和Chrome扩展的研究,本文设计的基于Chrome扩展的爬虫系统是一个严格的前后端分离的系统,信息抓取模块负责信息提取和结构化,中央服务器模块负责数据去重和持久化,两者之间没有业务上的重合。系统架构如图1所示。
图1系统架构
如图1所示,基于Chrome扩展的爬虫系统主要由3 个模块构成,即基于Chrome扩展的信息抓取模块、接受并处理Chrome扩展信息的中央服务器模块和进行数据存储的数据库模块。
l. 1中央服务器模块
中央服务器主要接受信息抓取模块的请求,根据需求返回配置数据或者接受抓取到的数据,并对接受的数据去重之后进行持久化。因为该过程不解析数据,所以相较于传统爬虫系统更节省资源。根据信息抓取模块的设计要求,刂」央服务器模块必须是一个支持高并发的后台系统。鉴于此,采用Netty框架艹田实现高并发。并且,为了整个爬虫系统的扩展性,中央服务器模块采用面向接凵编程思想,引人SpringLi2」对Bean进行管理。
I . 2信息抓取模块
信息抓取模块的主要任务是从网页中提取信息并且结构化,然后把结构化的数据用Ajax发送到中央服务器,其本质是Chrome浏览器的一一个扩展,是对浏览器功能的扩充。也正是该核心模块基于Chrome扩展,才能利用 Chrome扩展自有的性能,在工作量小于传统爬虫的同时,实现优于传统爬虫系统的功能。
信息抓取模块主要由3类文件构成,第一类是mani一 fest. j son文件,是Chrome扩展的配置文件;第二类是公有的JavaScript脚本文件,主要用于实现与中央服务器的交互并控制其它JavaScript脚本;第三类是从页面中提取信息的JavaScript脚本文件。
信息抓取模块有两个版本:一个是服务器版,根据从中央服务器获取的信息,自动打开网页并从中提取信息,当信息提取结束之后关闭该标签页,如果有必要会继续打开网页中的链接,并从链接页提取信息;另一个是普通用户版,与服务器版的区别在于不会从中央服务器获取信息并打开网页,而是当用户浏览网页的URL匹配网页抓取规则时,从网页中提取信息,不符合则不会进行信息提取。相对于服务器版,普通用户版不需要专门为了抓取数据而单独运行程序,也不会单独请求对方的服务器,不仅节约了用户的资源和时间,也减少了对方服务器的额外负载。
1.3主从数据库模块
为了满足中央服务器模块的高并发请求,对数据库采用主从库设计,主从库的设计不仅提高了数据读写的效率,而且提高了数据安全性。通过在中央服务器对JD一 BC接口的封装,使主库只承担写的功能,从库只承担读的功能。
2系统实现
本文设计的爬虫系统包含基于Chrome扩展的信息抓取模块、基于Netty的中央服务器模块和采用主从配置的数据库模块。其中,Chrome扩展模块分为个人版和服务器版,相对于个人版,服务器版的信息抓取模块更复杂。
图2是服务器版系统时序图。通过系统框架图、系统模块介绍和系统时序图可知,基于Chrome扩展的爬虫系统实现过程实际就是开发一个具有信息提取模块的 Chrome扩展,并且通过Netty框架实现一个支持高并发的中央服务器模块,即通过使用Chrome扩展和Netty框架技术,实现一个比现有爬虫系统更高效好用的爬虫系统。
2· 1中央服务器模块
中央服务器模块的主要功能是对信息抓取模块提交的信息进行去重并持久化。为了使系统支持高并发,引人 Netty框架和主从库设计;为了扩展方便,采用面向接凵编程思想,主要有HTTPServer、JDBC封装和API核心模块。修改ip
2 · l . I HTTPServer
HTTPServer主要实现创建服务端NI()线程组和端口监听。通过以下代码来实现服务端NIC)线程组设置:
EventLoopGroup bossGroup new NioEventLoopGroup
EventLoopGroup workerGroup new NioEventLoopGroup
ServerBootstrap serverBootstrap new ServerBootstrap
serverBootstrap
· group(bossGroup,workerGroup)
· channel(NioServerSocketChanneI. class)
· child()ption(ChannelOption. TCP NODELAY,true)
· child()ption(Channel()ption. CONNECT一TIMEOUT
MILLIS,60兴1000)
· childOption(ChannelOption. (C) REUSEADDR,true)
· option(ChannelOption. SO KEEPALIVE,true)
· child()ption(ChannelOption. ALLOCATOR,
PooledByteBufAJlocator. DEFAULT) · option(Channel()ption. SO BACKLOG' 4096)
· childHandler(new HttpServerInitializer());使用"serverBootstrap. bind( port) · sync() ;”来绑定监听端口,其中port是要监听的端口号。
2 · I. 2 JDBC封装
JI)BC(Java Database Connectivity)是Java提供的执行SQL语句的API,其封装了多种数据库的访问方式。本系统由于支持高并发和主从库设置,因而需要对J I)BC 进行封装以支持主从配置,提高与数据库交互的速度。
通过Java的Properties文件来配置主从库,并且通过 APIService来封装JDBC,所有查询操作都是用从库,所有更新或删除操作都使用主库。通过这种封装,不仅完成了读写分离,而且提高了效率。
2 · I . 3 API开发通过上述步骤,即可完成对中央处理模块核心功能的搭建。在此基础上,对不同主题信息进行抓取时,只需要开发对应的API即可。API的主要作用是接受Chrome 扩展发送的信息,并且对信息进行处理(验证是否为脏数据并去重等),将满足条件的数据写人主库。
在前面步骤基础上,开发API很简单,只需要注人
Bean和声明所需参数,然后在逻辑中验证参数即可。以添加赛程为例·
@APIContent(value " AddGame,description "添加赛事信息")
@DataRequest(value " AddGame',params一{ @ DataRequestParameter(name matchName,description一"耳关赛中文名"),
@DataRequestParameter( name ' homeTeamName丛de scription一'主队名称"),
name tion一"主队得分"),
@DataRequestParameter( name scription一"客队名称"),
@DataRequestParameter( homeScore ',descrip
(@ DataRequcstParamctcr(nameawayScore,escrjp— lion一"客队得分"),
年份勹, year
@DataRequestPararneter( name,description
@DataRequestParameter( name month",descrl[)tlon
"月份”),
@DataRequestParameter( nameday,description 天数"),
时间"),
@DataRequestParameter( name round",descriptIon
"轮次"), 丨
@DataRequestParameter(nametime,description
@DataRequestParameter(nameseasonId ,escrl[)tl()n
"赛季",defaultValue " 2 015《 ,required false) })其中,AddGame为Bean名称,也是类名称;DataRequestParameter表示该接口需要的参数,其中 name ”表小参数名称,“ description ”表示对参数名称的说明;required 表示该参数是否为必需
API类的属性和方法主要实现对数据的处理,例如验证必选参数是否有值、数据是否为脏数据等。将API从中央服务器的基础功能中分离出来,可极大增强系统的扩展功能。
2 · 2信息抓取模块信息抓取模块提取信息的本质是利用Chrome扩展自带的功能,对需要抓取信息的网页进行JavaScript脚本注人,然后利用JavaScript从HTML提取信息。但是信息抓取模块还需要其它功能,例如服务器版需要从中央服务器获取待抓取网页信息,在抓取结束时自动关闭标签页等;普通用丆」版需要控制是否运行扩展等,因而不仅需要信息提取脚本,还需要其它脚本。
2 · 2 · 1 manifest. json凸己置 manifest. json文件是Chrome扩.展的核心配置文件,对哪些网页注人哪些JavaScript脚本进行控制。为了从 soda抓取内容,manifest. json文件核心代码如卜:
/ /省略次要内容
" backgroud":{
persistent true, scrtpts common—3. 2,O.jest', CO re " back groud.js'ij
permtsslons notifications,storage tabs", cookies", "http://sodasoccer. com/ " ] content scripts
matches" :C"http://w .sodasoccer. com/ ' ] c55 core.J' ], common、一' 3,2, 0,js,core. JS,"soda.
//省略次要内容
其中,"background"属性表示Chrome扩展运行时会有脚本在后台运行,“ script "属性中的JavaScript文件就是在后台运行的脚本文件。"content-script ”属性控制哪些网页注人哪些脚本,其中“ matches "属性决定对哪些网页注人脚本,“js ”属性表示对网页注人哪些脚本。
2.2.2 backgroud. js文件 background.js文件是当Chrome扩展运行后会一直在后台运行的脚本文件。服务器版信息抓取模块用来控制浏览器打开哪些网页,即把从服务器获取的网页信息放人一个队列,background.js用来控制该队列的内容,当从队列中拿出信息,则打开一个网页,如果队列为空则再从服务器请求下一批网页信息。
2,2,3 core.js和core. css文件 core. js和core. css文件是公有基础文件,core,js文件主要用来和中央服务器交互,并且在调试时将页面提取到的信息按core、css文件申明的规则进行展示。
2.2,4 soda.js文件 soda.js文件是Chrome扩展信息抓取的核心文件,主要从网页中提取信息,并且如果网页有异步加载,则对异步加载网页进行处理。
(1 )普通信息提取功能。为了简化HTML和JavaScript之间的操作,信息提取功能主要使用Java&ript的一个版本库JQuerV14jo而从网页中提取信息主要使用JQuery
的选择器。,即通过浏览器自带的“审查元素”功能查看某一类网站的网页元素,然后使用J Query选择器从中提取内容。例如从5。uda中提取球队信息的代码如下:
$C1i" .zit'). each(function(index, ele—nt) { if (index chineseNa•e $(this). text()- replace("ü% )else if (index eng1ishNane:$(this)• text()• replace("英名
)else if (index ho—court生$(this). text(). replace(-主场
)else if (index == 4){
site = $(this)-text().replace("官网
(2)提取网页中的动态链接。有时需要打开网页链接
并从中抓取信息,但是某些网站的链接中含有动态生成的验证信息。传统爬虫系统很难解决该问题,因为其无法抓取网页的所有资源并使它们运行,然而对于Chrome扩展爬虫系统而言,这些信息与普通内容并无区别,因为提取
的链接本身就是从运行的浏览器中获取,因而必定带有最新的验证信息。
(3)从包含异步加载技术的网页中提取数据。随着网站浏览的激增,传统的Web同步请求模式已难以适应高并发高密度的网络请求,异步加载方式被越来越多的互联网服务提供商所采用]。相对于传统web技术,Ajax技术的广泛应用,不仅在一定程度上促进了页面表现和页面数据的分离,而且使web应用的交互特性、反应速度及柔性迈向了更高、更新的层次。。但Ajax技术对爬虫技术并不友好,传统的爬虫技术无法处理异步加载问题,即使专门针对异步加载的爬虫系统也需要调用浏览器API才能解决问题。但是基于Chrome扩展的爬虫系统只要使用JavaScript的setTimeout函数来控制信息抓取脚本的运行时机即可。例如,将信息提取功能放在一个函数中,然后使用SetTimeout函数延迟一定时间再执行信息抓取模块,这样可以确保网页中的异步加载信息完全加载结束。这样不仅解决了传统爬虫不能爬取异步加载的问题,而且相对于调用浏览器API大大降低了开发成本。
3系统验证
3,1安装扩展
安装爬虫扩展和Chrome其它扩展一样,根据安装程序来源可分为从Chrome应用商店获取和加载本地解压的扩展。对于本扩展,只需要在"chrome://extensions/ 页面勾选“开发者选项”,然后点击“加载已解压的扩展程序”即可运行。
3,2数据验证
山本文研究可知,系统可以从搜达足球@上抓取赛程。以英超为例,发现英超2015 / 2016赛季一共有38轮,每轮有10场比赛,总共有380场比赛。运行系统后,查询 game表,发现380场比赛都已完全抓到。图3为数据库中存储的2015 / 2016赛季英超的所有比赛,为了方便显示,删除了某些属性。
1 'id natchNane season-Id ganeDate honeTeanNane awayTeanNanerot.md
2016 2015一08.08 @:00:00切西 斯旺西
2016 201 08一08 00:00:00断特 德兰
20巧2015·08一08 00:00:00阿森纳 西汊
5 4英超2016即15删8一08 @:四:00堅彻断特联一.衽特纳坶一一.一一一.0、
378377英超 2016 201俨05一07 @;@:00利圄
379378英超 2016 201俨05一15 @:00:00埃弗顿
380《379英超 2016 201俨05一巧@:00:00身砌断特联伯恩茅断
381《3英超 2016 201 05一15 @:00:00沃特福桑德兰
图3英超赛程
3.3系统优点
通过上述实现过程可知,基于Chrome扩展的爬虫系统相较于传统爬虫系统具有以下优点:
o)开发简单。直接从浏览器解析好的页面中提取信息,省去了传统爬虫系统最难的步骤一一模拟浏览器。